1. Redis가 빠른이유!
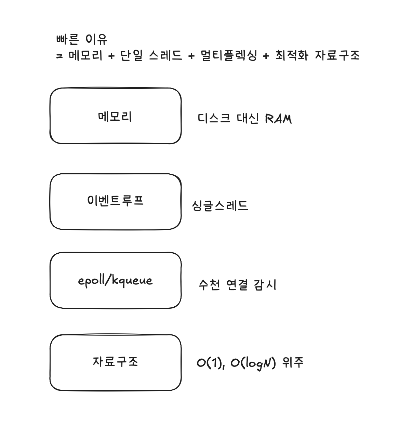
Redis는 단순히 메모리에 데이터를 저장하는 데이터 베이스라 속도가 빠른것이 아니다.(그런줄알았음ㅋ)
내부 구조와 I/O처리 방식이 일반 데이터 베이스와근본적으로 다르다!
1. In-Memory 기반
- 모든 데이터를 디스크가 아니라 메모리에 올려둔다 -> 디스크 I/O가 없다 (자료가 이미 RAM에있으니까!)
- 따라서 읽기/쓰기 속도가 밀리초가 아니라 마이크로초 단위!
2. 단일 스레드 + 이벤트 루프 구조
- Redis는 요청을 싱글 스레드가 처리함 (어디까지는 싱글스레드고 어디부턴 멀티스레드라고 하는데 더공부해야함 찾아보세용)
- 여러 스레드가 경쟁하는 구조가 아니기때문에 Lock경합이 없다 ! -> 동시성 제어 비용이 줄어든다
- 컨텍스트 스위치 비용도 극히적다
- 단일스레드라고 느린것이아니라 이벤트루프 + 논블로킹I/O + 멀티플렉싱 덕분에 수만개의 요청을 동시에 처리할수있음
3. I/O 멀티플렉싱(epoll, kqueue 등)
- 리눅스의 epoll 시스템 콜을 이용해서 여러 소켓 (클라이언트 연결)을 동시에 감시
- 특정 소켓에서 읽기/쓰기 가능 상태가 되면 이벤트로 감지해서 즉시처리
- 그래서 하나의 스레드가 수천개의 연결을 동시에 처리할수있다!
- 대량연결을 스레드 하나로 효율적으로 관리하고 놀지않고 계속 준비된일만 한다..
4. 자료구조 최적화
- 대부분 명령이 O(1)~ O(logN)
- HashTable, Ziplist/Quicklist, Skiplist(ZSET), HyperLogLog, Bitmaps 등 메모리 친화 자료구조
5. 프로토콜 단순 + 파이프라이닝
- 텍스트에 가까운 단순 프로토콜로 파싱 비용이 낮다!
- 클라이언트가 여러 명령을 한꺼번에 보내서 RTT(Round Trip Time : 왕복지연)을 줄인다
(RTT: 네트워크에서 데이터 패킷이 발신지에서 목적지까지 갔다가 다시 발신지로 돌아오는 데 걸리는 시간)
(파이프라이닝 : CPU가 시간을 알뜰살뜰하게 사용해서 명령어를 처리하는 기법 -> 인출해석실행저장안겹치면 동시에 ㄱㄱ~)
6. 디스크 작업의 격리 (지연/백그라운드)
- AOF/RedisDB는 fork + copy-on-write로 백그라운드 처리 -> 메인루프 방해 최소화
Redis 관점에서 fork + Copy-On-Write
1. Redis는 싱글 스레드 이벤트 루프
- 메인 루프는 모든 클라이언트 요청 처리(GET/SET, Hash, ZSet…)를 맡음
- 이 루프가 잠깐이라도 멈추면 전체 서비스 지연 → 디스크 작업 같은 무거운 건 메인 루프에서 못 함
-> 그래서 백그라운드 프로세스를 따로 만들어야 함
2. RedisDB/AOF 백업 과정에서 fork() 사용
- RedisDB 저장: 메모리 전체를 덤프 → .rdb 파일로 기록해야 함
- AOF 리라이트: append-only 파일이 너무 커졌을 때 압축/정리 필요
이때 메인 루프가 직접 메모리 → 파일 쓰기를 하면 수십~수백 ms 동안 요청 처리가 멈출 수 있음
→ Redis는 fork() 해서 자식 프로세스가 백업을 담당
- 부모(메인 루프)는 계속 요청 처리
- 자식은 메모리 상태를 파일로 저장
3. Copy-On-Write (COW) 덕분에 효율적
- fork()를 하면 부모 프로세스의 주소 공간 전체를 자식이 !!!공유!!!
- 실제로 복사하는 게 아니라 읽기 전용으로 같은 페이지를 바라봄
- Redis는 메모리에 수 GB 데이터를 들고 있을 수 있는데, 이걸진짜로 복사하면 시간·메모리 모두 폭발 → 불가능
-> COW 방식:
- 부모(메인 루프)나 자식이 읽기만 하면 복사 없음 → 빠름
- 부모가 쓰기(SET, INCR 등) 하면 해당 페이지를 그때 복사 → 부모만 새로운 페이지 사용
4. Redis에서의 의미
- 메인 루프 방해 최소화: 요청 처리는 계속 진행, 자식은 스냅샷 기록
- 메모리 효율: fork 직후에는 추가 메모리 거의 안 씀(쓰기 많은 workload에서는 COW 복사가 늘어남)
- 안정성: 파일 기록 중 장애가 나도 부모 프로세스는 영향 없음
5. 단점도 있음
- fork는 OS 레벨에서 전체 주소 공간을 복사해야 하므로, 메모리가 클수록 fork 자체가 수십~수백 ms 걸릴 수 있음
- Copy-On-Write도 쓰기 많은 시점에는 메모리 사용량 급증 가능
- 그래서 대규모 운영환경에선 fork() 자체를 줄이는 최적화 기법(예: RDB 대신 AOF만, 또는 주기 조절)을 고민함
- fork = Redis가 자식 프로세스를 만들어서 RDB/AOF 파일 기록을 맡김
- Copy-On-Write = 자식이 부모 메모리를 공유하다가, 쓰기 발생 시에만 실제 복사 → 메모리/성능 절약
- Redis 철학: 메인 루프는 클라이언트 요청만 담당 → 백업/영속성은 fork된 자식이 처리
-> 메모리 기반 + 단일 스레드 이벤트 루프 + IO 멀티플렉싱 이기때문에 빠른거다~
단순 인메모리기반이라서 빠른게 아니다~
2. 블로킹 vs 논블러킹
자자 블로킹 논블로킹이 무엇이냐..


블로킹 : 한요청이 끝날때까지 다른요청 대기 (병목발생)
논블로킹 + 멀티플렉싱 : 요청이 완료될때까지 기다리지않고 다른요청을 동시에 처리! -> CPU 못놀게함
* 논블로킹 주의점
유후 시간이없고 (대기하지않고 다른 소켓처리) -> CPU 활용 극대화
스레드수가 적어 메모리/스케줄러 부담이 적어진다는 장점이있지만
오래걸리는명령 (`Keys *` , 대용량`SORT` 대형 Lua스크립트 )은 이벤트 루프를 막는다 -> 전체 지연급증
-> SCAN , 제한된 범위연산 , shard/분해, 백그라운드 작업으로 회피 고고
나중에 보려고 적은 개념~
1. I/O(Input/Output)
프로세스가 네트워크 소켓, 디스크, 터미널등 외부와 데이터를 주고받는 행위
CPU는 빠르지만 I/O는 상대적으로 느리다(네트워크 왕복, 디스크 접근 등)
서버성능의 병목은 대부분 I/O에서 생긴다.
2. 블로킹/논블로킹/비동기
블로킹 I/O : read()했는데 아직 올 데이터가 없다면 그냥 기다림 -> 스레드 놀기
논블로킹 I/O : read()했는데 없으면 바로 없음(EAGAIN) 리턴하고 돌아옴 -> 스레드는 딴일하다가 나중에 다시 읽으러감
비동기 I/O : 커널이 끝날때 알아서 알려줌 (완료이벤트 -> 리눅스의 io_uring 같은모델)
-> 레디스는 이거말구 멀티플렉싱씀
3. 멀티플렉싱(select/poll/epoll...)
여러 소켓을 한 스레드가 동시에 감시하는 기술
리눅스에서는 epoll을 주로 사용
커널이 이 소켓 읽기 가능~ 저 소켓 쓰기가능~~ 같은 이벤트를 모아서 알려준다 쉴수없음
그래서 스레드하나가 수천개의 연결을 효율적으로 다룰수있다! (소켓마다 스레드 하나씩아님 -> 컨텍스트 스위치 , 락경합없음)
3. 이벤트 루프란?
이벤트(입출력 가능 신호)를 받으면서 한바퀴씩 도는 메인루프
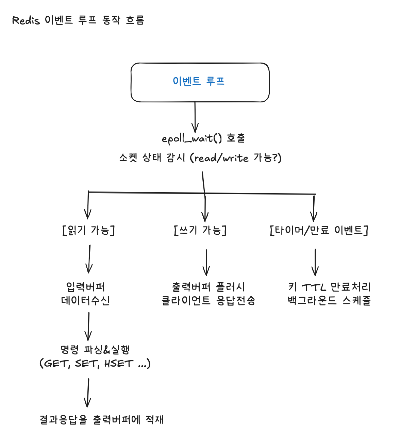
구현 코드~
while (running) {
ready = epoll_wait(); // 읽기/쓰기 가능한 소켓 목록 받기
for (fd in ready.readables) readFromClient(fd); // 입력 버퍼 채우기
processCommands(); // 버퍼에 쌓인 명령을 파싱/실행
for (fd in ready.writables) writeToClient(fd); // 응답을 소켓에 씀
runScheduledTasks(); // 주기 작업(aof fsync 스케줄, 만료 처리 등)
}- 싱글스레드가 이 루프를 돈다 !
- 각 단계는 짧고 빠르게 끝내도록 설계해야된다 (오래걸리면 전체가 막힌다 -> O(N)명령어 절대안댐 궁금하면 해바~ )
Redis 6부터는 I/O전용 보조 스레드 (읽기/쓰기)를 선택적으로 켤수있지만 , 명령 실행자체는 여전히 메인스레드가한다구함(기본동작은 동일 )
4. 스프링 적용시 포인트
- 클라이언트 드라이버
- Lettuce: Netty 기반, 비동기/논블로킹 지원, 파이프라인/리액티브 적합. (요즘 기본)
- Jedis: 전통적 동기 스타일(최근엔 풀로 보완).
- @Cacheable: 키-값 캐시엔 간단하고 빠르당 -> 전에 컨피그 파일 설정하기
- RedisTemplate: Hash/Set/ZSet 등 자료구조를 직접 써야 할 때
- Redisson: 분산락/세마포어 등 고급 동시성 도구
세마포어(Semaphore)는 컴퓨터 과학에서 공유 자원에 대한 접근을 제어하는 메커니즘
특히 멀티프로그래밍 환경에서 여러 프로세스나 스레드가 동시에 공유 자원에 접근하는 것을 방지하여 데이터의 일관성과 시스템의 안정성을 유지하는 데 사용한다!!!!!!!!!!
5. 정리

Network (epoll 기반)
- 클라이언트 소켓들을 리눅스 epoll로 멀티플렉싱(여러 소켓을 한 스레드가 동시에 감시)
- “읽기/쓰기 가능” 상태가 되면 커널이 알려줌 → 불필요한 대기 없음
[Event Loop]
- 메인 스레드가 한 바퀴씩 도는 루프
- 매 틱(tick)마다:
- epoll_wait()로 준비된 소켓 목록 받음
- 입력 버퍼 읽기 → 명령 파싱/실행
- 출력 버퍼를 쓰기 가능 소켓으로 플러시
- 예약 작업(만료 처리, 타이머, 내부 유지보수) 수행
- 싱글 스레드라 전역 락 거의 없음 → 컨텍스트 스위치/락 경합 비용이 매우 낮음
Storage In-Memory (자료구조: Hash, List, Set, ZSet, Bitmap …)
- 모든 데이터가 RAM에 있음 → 디스크 I/O 없는 μs~ms 응답
- 연산의 시간복잡도가 O(1)~O(logN)가 되도록 자료구조가 최적화돼 있음(예: ZSET=skiplist+hash)
Background Thread (AOF, Redis DB 스냅샷 저장, 복제/클러스터 통신 등)
- 메인 루프를 방해하지 않도록 백그라운드에서 디스크/네트워크 집약 작업 처리
- 스냅샷 시 fork + Copy-On-Write로 RedisDB 파일 생성, AOF 리라이트, 복제/클러스터 메시지 등
무한반복 ~ 메모리 + 이벤트 루프 + epoll + 최적화 자료구조 + 백그라운드 오프로딩 조합이 빨라지는 이유~~
AOF (Append Only File)
- 개념
- Redis의 쓰기 명령(SET, HSET, INCR …) 을 그대로 로그 형태로 파일에 기록.
- 재시작 시 AOF를 순서대로 “리플레이”해서 메모리 상태를 복원.
- 장점
- 가장 안전 (fsync 모드에 따라 거의 무손실 복구 가능).
- append-only 방식이라 파일 손상 위험이 적음.
- 단점
- 파일 크기가 커짐 → Rewrite(압축) 과정 필요.
- 디스크 I/O 부담이 RDB보다 크다.
- 설정
- appendonly yes
- appendfsync always/everysec/no (성능↔안정성 트레이드오프)
Redis Database Snapshot
- 개념
- 특정 시점의 메모리 상태를 덤프(snapshot) 해서 .rdb 파일로 저장.
- 장점
- 파일 크기가 작음 → 백업/전송 유리.
- 읽어 복원하는 속도 빠름.
- 단점
- 마지막 스냅샷 이후 데이터 유실 가능성 있음.
- 저장 시점에 fork를 쓰므로 순간적으로 메모리 사용량 증가.
- 설정
- save 900 1 (900초 동안 1회 이상 변경 시)
- save 300 10 (300초 동안 10회 이상 변경 시)
- 이런 조건으로 자동 스냅샷 생성.
복제 (Replication)
- 개념
- 하나의 Master → 여러 Slave 구조.
- 동작
- 최초에는 Master RDB 스냅샷을 통째로 전송 후,
- 이후에는 명령어 스트림(리플리케이션 로그) 으로 동기화.
- 장점
- 읽기 부하 분산(슬레이브 read-only 가능).
- 장애 시 슬레이브를 승격하여 HA 가능.
- 단점
- 기본적으로 비동기 복제 → 일부 데이터 손실 가능.
- (Redis 2.8부터 부분 재동기화 지원 → 네트워크 끊겨도 delta만 재전송)
클러스터 (Cluster)
- 개념
- Redis를 샤딩 기반 분산 DB처럼 사용. (16384 hash slot으로 키를 분산)
- 동작
- 각 노드가 특정 slot 담당.
- 노드 간 하트비트(heartbeat) + gossip 프로토콜로 상태 공유.
- 마스터-슬레이브 쌍 구성 → 마스터 장애 시 자동 failover.
- 장점
- 수평 확장 가능.
- 데이터 자동 분산 & 고가용성.
- 단점
- 멀티 키 연산/트랜잭션 제약 있음.
- 클러스터 복잡성 증가.
AOF + RedisDB + 복제 + 클러스터 조합
- AOF + RedisDB 동시 사용
- Redis는 보통 AOF + RDB 둘 다 활성화해서 안전성 + 빠른 복구를 동시에 가져감.
- Replication
- Master 장애 시 대비 + read scale-out.
- Cluster
- 데이터가 많아지면 샤딩 & 분산.
- Sentinel
- 단일 Master-Replica 구조에서 자동 장애 조치(HA) 관리. (Cluster와 별개 개념)
'공부일기.. > Spring' 카테고리의 다른 글
| [Spring Boot] application.yml 설정파일 마스타~~ (0) | 2025.09.14 |
|---|---|
| [Spring-legacy] 이거 @RequestBody Map으로 받아도 되나요? (1) | 2025.08.27 |
| Redis 활용시 직렬화/역직렬화를 해야하는 이유 (ObjectMapper) (4) | 2025.08.17 |
| Redis 캐시1 - RedisCacheManager (@Cacheable) 사용하기 (3) | 2025.08.16 |
| [Spring Boot] 게시판 만들기③ | EC2에 배포하고 실행까지 따라하기 (0) | 2025.07.06 |